Spacetime Gaussian Feature Splatting for Real-Time Dynamic View Synthesis
1

1
Real-time interactive demo and spiral path rendering. Scenes are from Google Immersive [1], Technicolor [2], and Neural 3D Video [3] datasets. *The visualization of the Gaussians is inspired by Luma AI.
Novel view synthesis of dynamic scenes has been an intriguing yet challenging problem. Despite recent advancements, simultaneously achieving high-resolution photorealistic results, real-time rendering, and compact storage remains a formidable task. To address these challenges, we propose Spacetime Gaussian Feature Splatting as a novel dynamic scene representation, composed of three pivotal components.
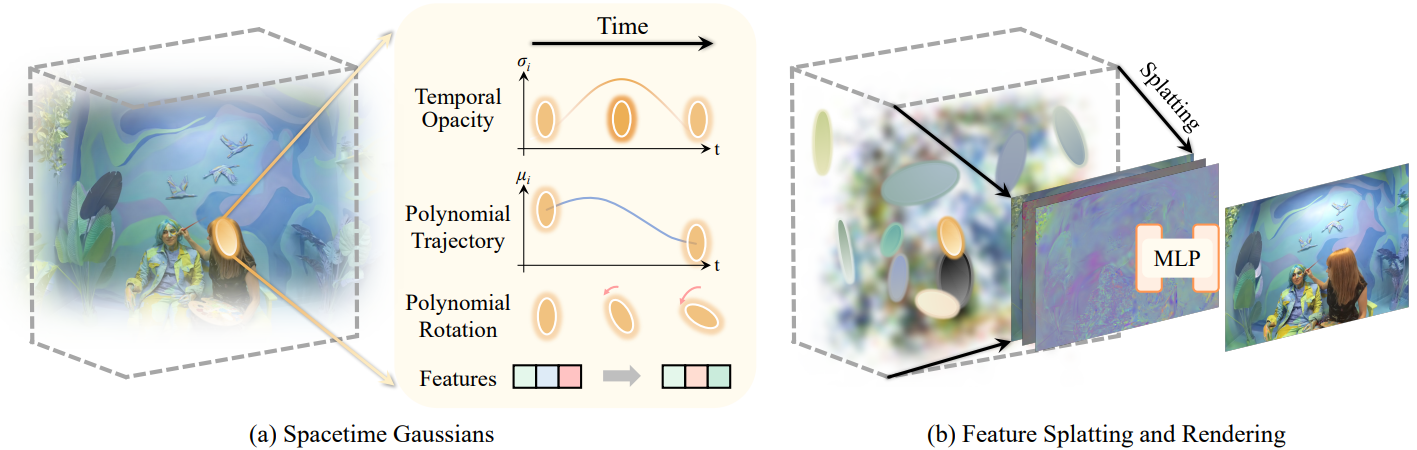
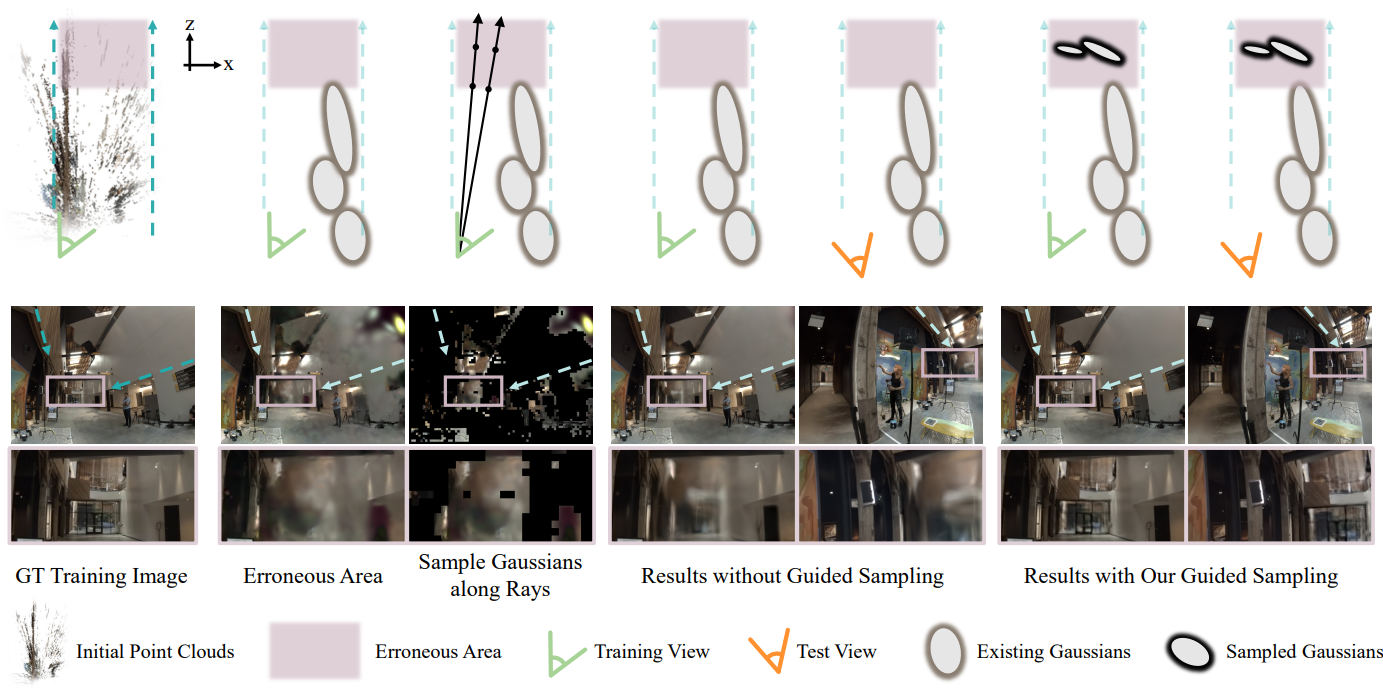
First, we formulate expressive Spacetime Gaussians by enhancing 3D Gaussians with temporal opacity and parametric motion/rotation. This enables Spacetime Gaussians to capture static, dynamic, as well as transient content within a scene. Second, we introduce splatted feature rendering, which replaces spherical harmonics with neural features. These features facilitate the modeling of view- and time-dependent appearance while maintaining small size. Third, we leverage the guidance of training error and coarse depth to sample new Gaussians in areas that are challenging to converge with existing pipelines.
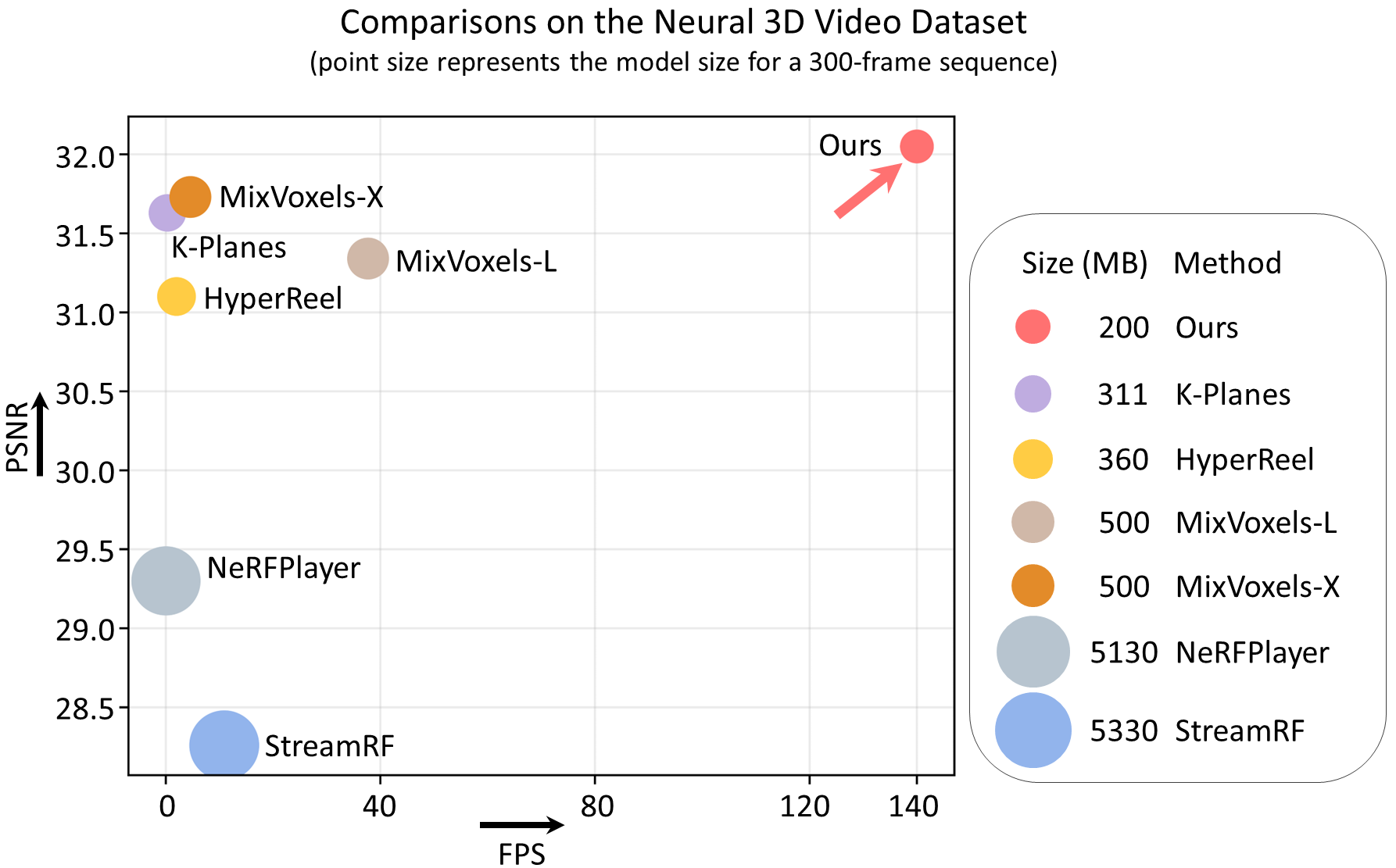
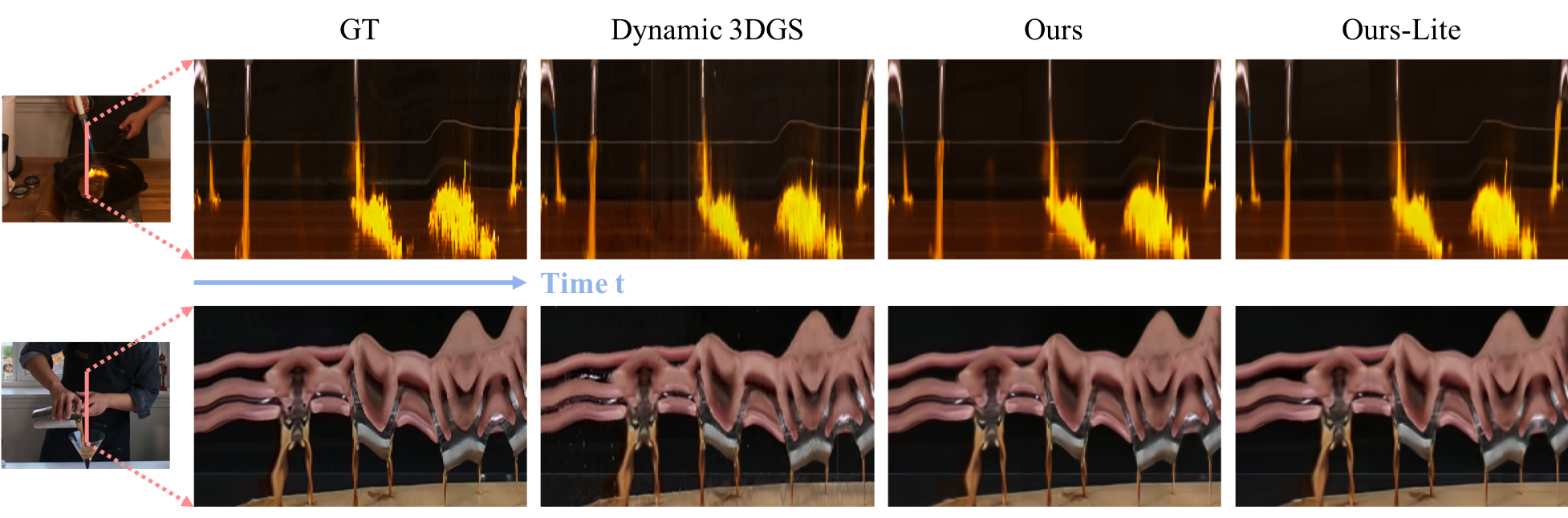
Experiments on several established real-world datasets demonstrate that our method achieves state-of-the-art rendering quality and speed, while retaining compact storage. At 8K resolution, our lite-version model can render at 60 FPS on an Nvidia RTX 4090 GPU.




















@article{li2023spacetime,
title={Spacetime Gaussian Feature Splatting for Real-Time Dynamic View Synthesis},
author={Li, Zhan and Chen, Zhang and Li, Zhong and Xu, Yi},
journal={arXiv preprint arXiv:2312.16812},
year={2023}
}